ONE-SHOT: Compositional Human-Environment Video Synthesis via Spatial-Decoupled Motion Injection and Hybrid Context Integration
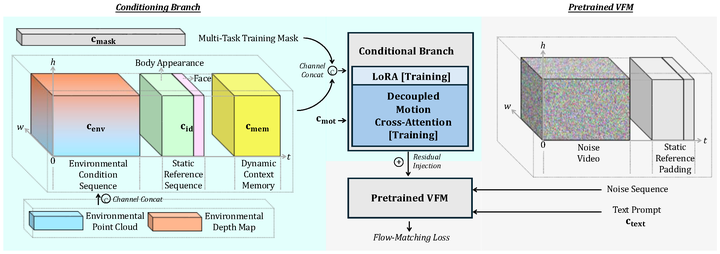 The framework overview of ONE-SHOT.
The framework overview of ONE-SHOT.
Abstract
Recent advances in Video Foundation Models (VFMs) have revolutionized human-centric video synthesis, yet fine-grained and independent editing of subjects and scenes remains a critical challenge. Recent attempts to incorporate richer environment control through rigid 3D geometric compositions often encounter a stark trade-off between precise control and generative flexibility. Furthermore, heavy 3D pre-processing still limits practical scalability. In this paper, we propose ONE-SHOT, a parameter-efficient framework for compositional human-environment video generation. Our key insight is to factorize generative process into disentangled signals. Specifically, we introduce a canonical-space injection mechanism that decouples human dynamics from environmental cues via cross-attention. We also propose Dynamic-Grounded-RoPE, a novel positional embedding strategy that establishes spatial correspondences between disparate spatial domains without any heuristic 3D alignments. To support long-horizon synthesis, we introduce a Hybrid Context Integration mechanism to maintain subject and scene consistency across minute-level generations. Experiments demonstrate that our method significantly outperforms state-of-the-art methods, offering superior structural control and creative diversity for video synthesis.
Fengyuan Yang
PhD. student in Computer Science
My research focuses on human-centric motion reconstruction and video generation. I explore both directions: recovering human motion, camera movement, and scene background from videos, as well as generating new videos by flexibly combining these decomposed elements. Previously, during my Master’s studies, I explored the incorporation of semantic knowledge in Few-Shot Learning.