SEGA: Semantic Guided Attention on Visual Prototype for Few-Shot Learning
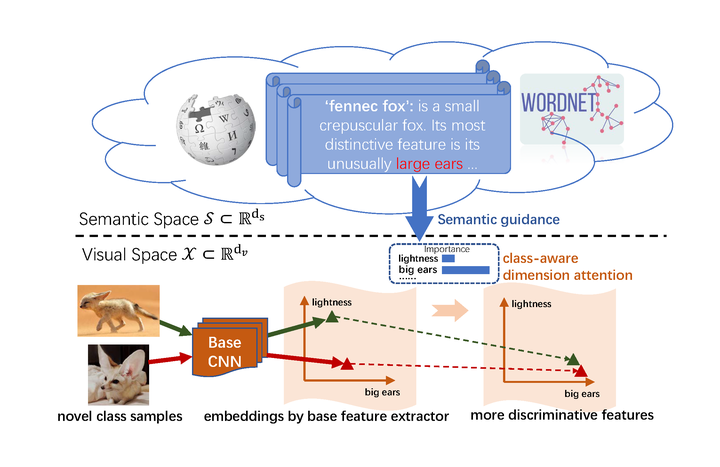 The illustration diagram shows the motivation of ours semantic guided attention.
The illustration diagram shows the motivation of ours semantic guided attention.
Abstract
Teaching machines to recognize a new category based on few training samples especially only one remains challenging owing to the incomprehensive understanding of the novel category caused by the lack of data. However, human can learn new classes quickly even given few samples since human can tell what discriminative features should be focused on about each category based on both the visual and semantic prior knowledge. To better utilize those prior knowledge, we propose the SEmantic Guided Attention (SEGA) mechanism where the semantic knowledge is used to guide the visual perception in a top-down manner about what visual features should be paid attention to when distinguishing a category from the others. As a result, the embedding of the novel class even with few samples can be more discriminative. Concretely, a feature extractor is trained to embed few images of each novel class into a visual prototype with the help of transferring visual prior knowledge from base classes. Then we learn a network that maps semantic knowledge to category-specific attention vectors which will be used to perform feature selection to enhance the visual prototypes. Extensive experiments on miniImageNet, tieredImageNet, CIFAR-FS, and CUB indicate that our semantic guided attention realizes anticipated function and outperforms state-of-the-art results.
Fengyuan Yang
PhD. student in Computer Science
My research interests encompass the field of Computer Vision, with a particular emphasis on Human Pose Estimation in the world coordinate during my Ph.D. Previously, during my Master’s studies, I explored the incorporation of semantic knowledge in Few-Shot Learning.